Canal搭建与使用
Canal 简介
Canal [kə’næl],译意为水道/管道/沟渠,是阿里巴巴开源的一个 MySQL 数据库增量订阅和消费中间件,将自己伪装成 MySQL 的从库,获取 MySQL 的 binlog(二进制日志)数据,从而实现对数据库变更的实时监听。
官方地址:https://github.com/alibaba/canal 。
实现思路
Canal 通过解析数据库的 binlog 日志 捕获数据变更。
将变更数据实时同步到下游服务,如更新 Elasticsearch 索引。
优点
零侵入:
不需要修改业务服务逻辑,无需在代码中额外发送消息。
直接从 binlog 获取数据变更,减少对业务代码的侵入性。
一致性强:
- Canal 直接从数据库日志解析数据变更,与数据库主数据完全一致。
低耦合:
- 不依赖业务服务的实现,与数据库交互即可实现同步。
实时性高:
- 通过解析 binlog,变更数据可以实时同步到搜索服务。
缺点
运维成本高:
Canal 需要独立部署,并且对高并发的 binlog 解析有较高的硬件要求。
Canal 本身也需要高可用方案(如集群模式)。
功能有限:
Canal 只能捕获数据库变更(新增、修改、删除),难以处理复杂的业务逻辑(如某些需要额外字段加工的消息)。
如果业务中对数据的更新不是直接写入数据库,而是通过缓存(如 Redis),Canal 无法捕获。
数据处理复杂性:
Canal 只能获取到原始数据变更,需要额外开发逻辑将 binlog 数据转换为 Elasticsearch 所需的格式。
多表关联、字段映射等逻辑可能增加实现复杂性。
数据库依赖:
- Canal 强依赖数据库的 binlog 格式(如 MySQL Binlog),对某些数据库(如 NoSQL 或非 MySQL 系统)支持有限。
Canal 通过 Docker 安装
- 下载镜像
docker pull elasticsearch:7.3.0
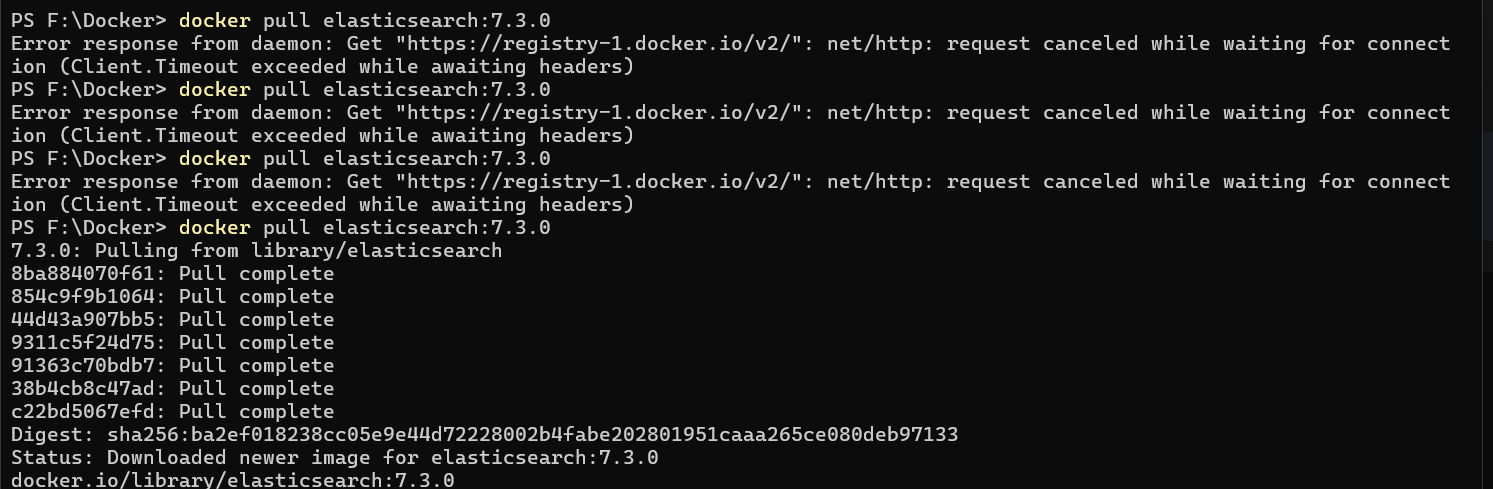
执行 docker images 查看镜像是否挂载成功:

- 准备挂载文件夹
接着,在 F:\Docker 文件夹下创建 /elasticsearch 文件夹,用于等会跑 es 容器时,将容器内部需要持久化的相关文件夹挂载出来:
- 运行 Docker 容器
命令行运行如下命令,先跑一个 Elasticsearch 7.3.0 版本的 Docker 容器:
1 | |
命令各项参数的含义:
docker run:启动一个新的容器。-d:表示以 后台运行(detached mode)。--name es7: 给这个容器指定一个名字为es7,方便后续管理和识别。-p 9200:9200 -p 9300:9300:端口映射,将容器内的端口暴露到主机上:9200:9200:将容器内的 9200 端口(Elasticsearch 的 REST API 接口)映射到主机的 9200 端口,供外部使用。9300:9300:将容器内的 9300 端口(Elasticsearch 的内部通信端口,用于节点间通信)映射到主机的 9300 端口。
-e "discovery.type=single-node":通过环境变量设置 Elasticsearch 以 单节点模式 运行:作用:避免集群模式下的主节点选举。
场景:适用于开发、测试环境,不需要集群功能。
-e ES_JAVA_OPTS="-Xms1024m -Xmx1024m":设置 JVM 内存参数:-
Xms1024m:设置 JVM 的初始堆内存为 1024MB。-Xmx1024m:设置 JVM 的最大堆内存为 1024MB。作用:确保 Elasticsearch 启动时使用 1GB 固定堆内存(建议与物理内存配置匹配,以提高性能)。
elasticsearch:7.3.0:指定使用的 Docker 镜像为elasticsearch:7.3.0。
运行 docker ps 命令,确认 Elasticsearch 7.x 容器是否运行成功:

- 复制需要挂载的文件夹
执行如下命令,将 es 容器内部的相关文件夹,复制到宿主机的 F:\Docker\elasticsearch 文件夹下:
1 | |
解释一下这几个文件夹的作用:
/config: Elasticsearch 的默认配置文件,便于后续修改配置,如 elasticsearch.yml、jvm.options 等;/data: Elasticsearch 的索引、文档等数据;/plugins: Elasticsearch 相关插件;
- 修改配置
编辑刚刚复制出来的 /config 中的 elasticsearch.yml 配置文件,修改如下:
1 | |
修改了集群名称
cluster.name为xxx;添加了跨域相关配置;
- 重新启动容器
执行如下命令,将正在运行中的 es 容器强制删除掉:
1 | |
重新跑一个新的 es 容器,注意,这次命令中需要添加挂载文件夹参数,用于将数据、配置、插件都挂载出来,防止容器停止/删除后,相关数据丢失的问题:
1 | |

- 确认容器是否运行成功
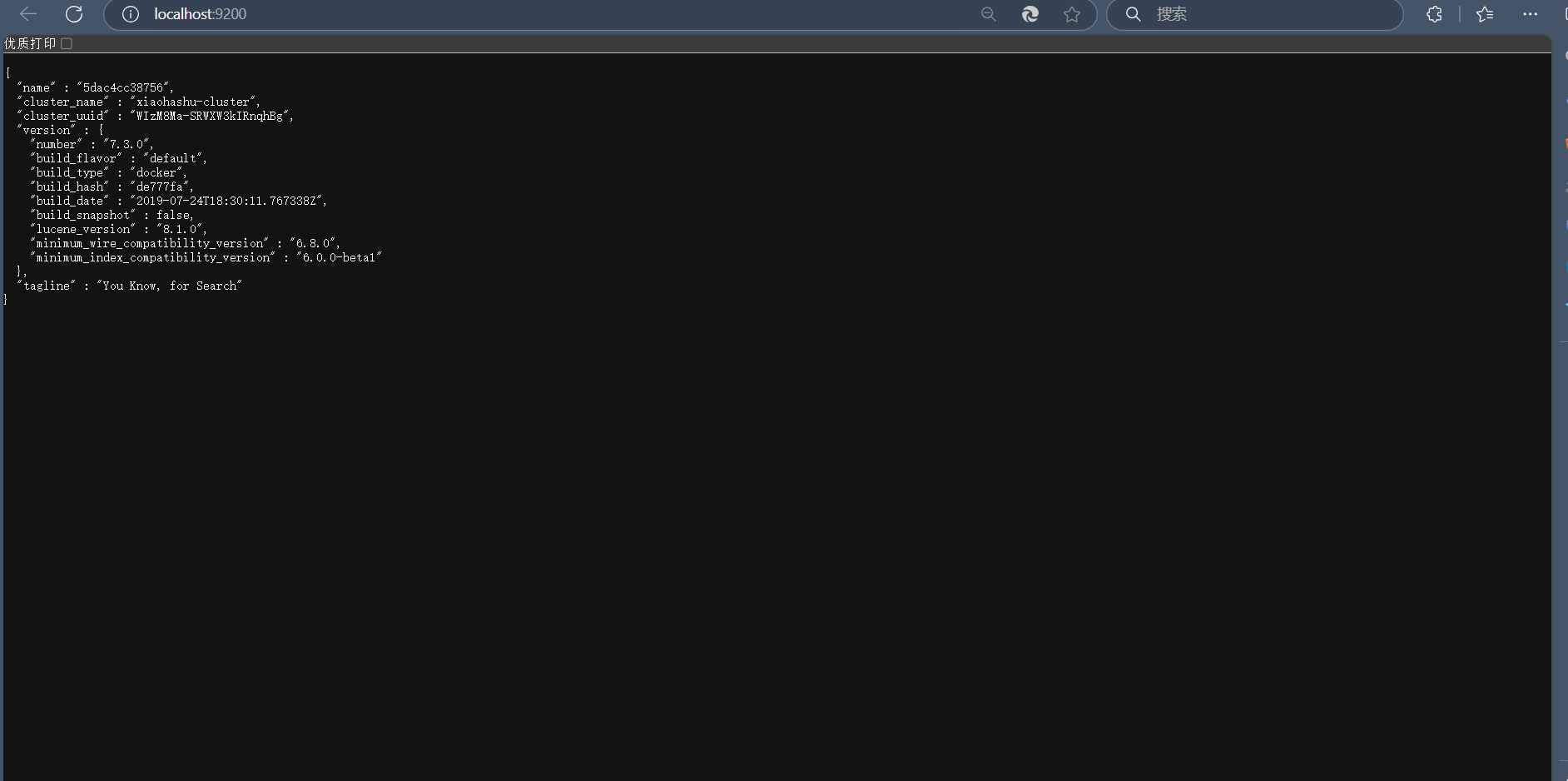
浏览器访问地址:http://localhost:9200/ ,若如下图所示,返回了 es 相关信息,说明本地单节点的 es 环境就搭建好了:
安装 elasticsearch-head 可视化工具
elasticsearch-head 是一个开源的 Web 前端工具,用于 管理和可视化 Elasticsearch 集群。它提供了用户友好的界面,让用户能够直观地查看集群状态、管理索引、运行查询等操作。
官方地址:https://github.com/mobz/elasticsearch-head 。
- 下载 head 镜像
我们将通过 Docker 把 elasticsearch-head 工具跑起来,执行如下命令,以下载镜像:
1 | |
- 运行 head 容器
执行如下命令,运行 elasticsearch-head 容器:
1 | |
- 访问 head 控制台
elasticsearch-head 容器运行成功后,浏览器访问地址:http://localhost:9100/ ,即可访问控制台,如下图所示:
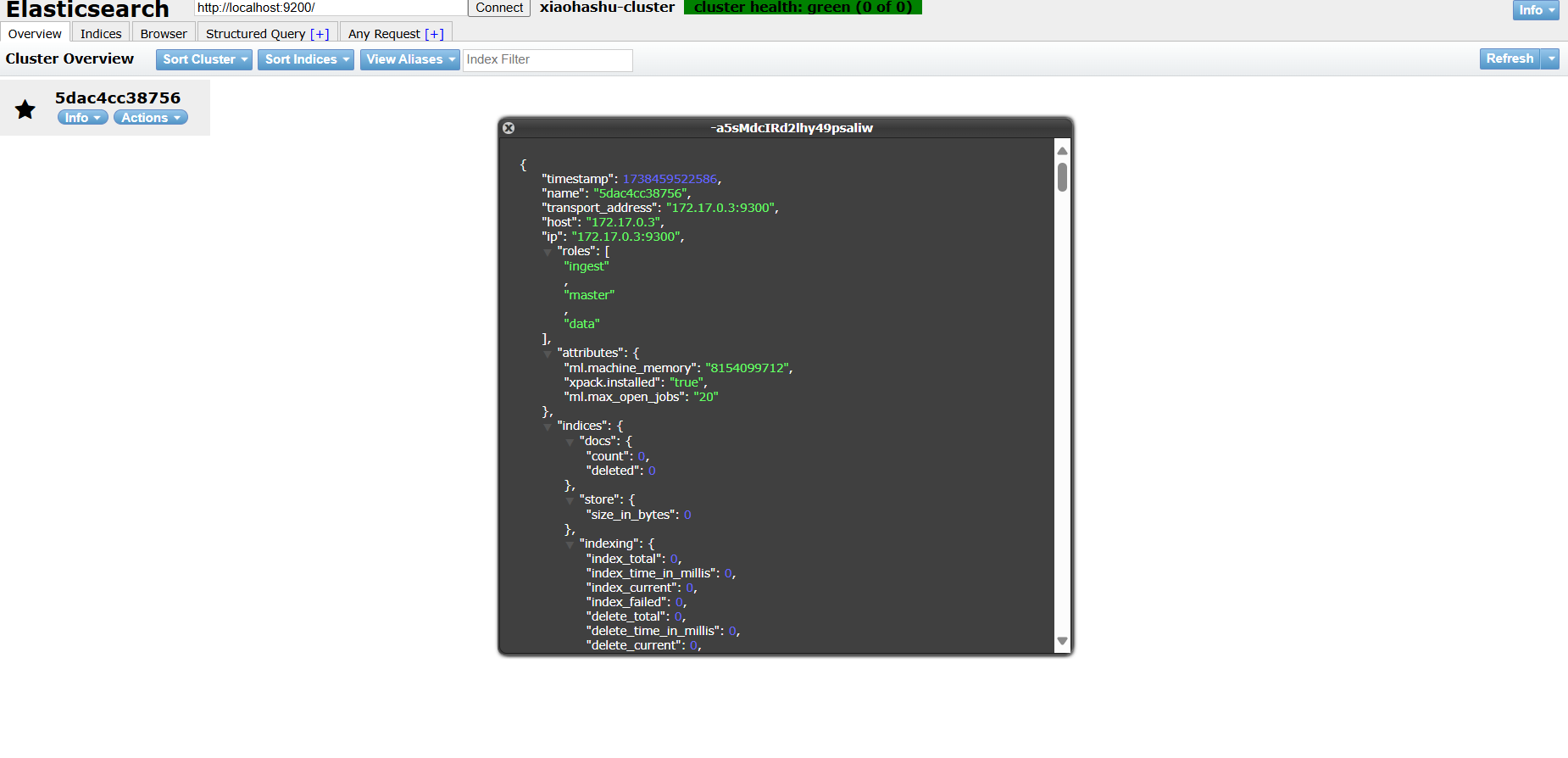
①:点击连接按钮,若提示集群健康值为 green, 则表示 elasticsearch-head 连接 es 集群正常;
②:在集群概览中,可查看当前正在运行的集群节点数,当前是一个节点;
③:点击查看集群节点信息,如图所示,可以看到 cluster.name 集群名称确实是我们定义的 xiaohashu-cluster ;
Elasticsearch 核心概念介绍
什么是 Elasticsearch?
Elasticsearch 是一个开源的分布式搜索和分析引擎,能够对海量数据进行快速的存储、搜索和分析。它基于 Apache Lucene 构建,为全文搜索、结构化搜索和数据分析提供了一种高效且易于使用的解决方案。
其特性如下:
分布式架构:Elasticsearch 天生支持分布式,可以轻松扩展至数百个节点。
实时搜索:能够对新增数据快速进行搜索和查询。
全文检索:支持强大的全文搜索功能,包括模糊匹配、分词、高亮显示等。
RESTful API:提供易于使用的 HTTP 接口,方便与其他系统集成。
高度可定制:支持自定义分词器、查询语法和分析器,适应各种复杂业务需求。
开放与可扩展性:插件化设计,允许根据需求扩展功能。
Elasticsearch 核心概念
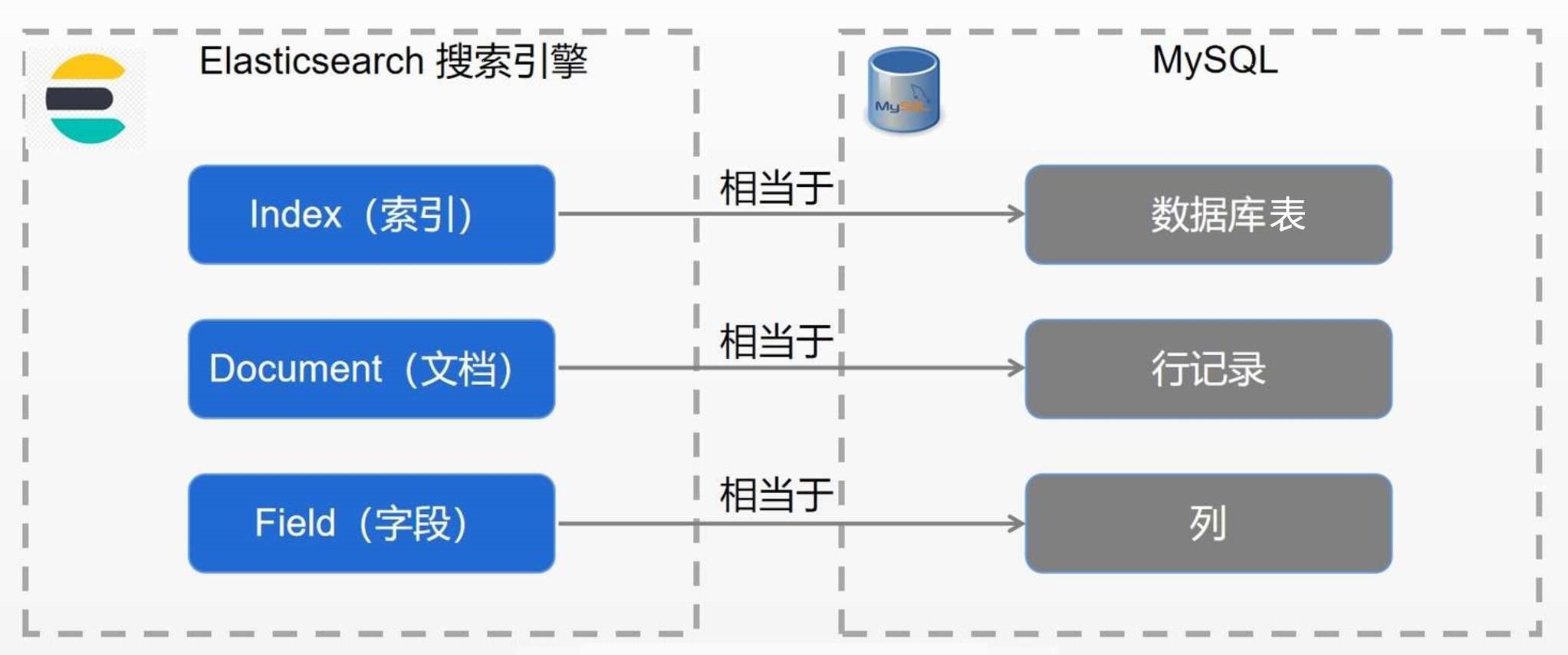
Index(索引):索引是 Elasticsearch 的数据存储单位,类似于关系型数据库中的 “Table(表)”。
Document(文档):文档是 Elasticsearch 中的最小数据单位,类似于关系型数据库中的 “Row(行)”。
Field(字段):字段是文档的属性,类似于关系型数据库中的 “Column(列)”。
Type(类型):在 Elasticsearch 7.x 版本后,Type 的概念被逐渐废弃,统一默认值为 _doc, 以简化架构设计。
Cluster(集群):Elasticsearch 的集群由一个或多个节点组成,共同提供存储、搜索和分析服务。
Node(节点): 集群中的每个实例被称为节点,每个节点可以存储部分数据并参与集群的计算任务。
Shard(分片)和 Replica(副本):
Shard(分片): 索引被分为多个分片,每个分片可以独立存储和查询。
Replica(副本): 分片的副本,用于提高查询效率和容错能力。
Elasticsearch 的应用场景
日志和事件数据分析 : 与 Logstash、Kibana 组成 ELK Stack,用于收集、存储、分析日志数据,实现实时监控和告警。
全文搜索 : 支持复杂的文本搜索功能,可用于搜索引擎、文档管理系统等场景。
推荐系统 : 通过聚合分析和个性化查询,为电商、内容平台等提供推荐服务。
数据分析与 BI : 可对结构化和非结构化数据进行复杂聚合分析,适用于数据报表和业务决策。