BloomRedis安装与使用
什么是 RedisBloom?
RedisBloom 是 Redis 的一个模块,它专门用于实现各种概率性数据结构,以节省内存和提升性能,适合在高并发的场景下使用。
RedisBloom 提供了布隆过滤器 (Bloom Filter)、Count-Min Sketch、布谷鸟过滤器 (Cuckoo Filter)、以及 Top-K 数据结构等。[官方地址](https://github.com/RedisBloom/RedisBloom [官方地址])
RedisBloom 提供的几种核心数据结构介绍:
布隆过滤器 (Bloom Filter):布隆过滤器是一种非常高效的概率性数据结构,用于快速判断某个元素是否存在于一个集合中。它的优势在于节省内存、支持高并发操作,适用于需要快速判断“是否存在”且能容忍一定程度误判的场景。
Count-Min Sketch:Count-Min Sketch 是一种概率性数据结构,用于统计流式数据中元素的频率。相比于传统的哈希表,它能够以非常少的内存实现近似频率统计。
布谷鸟过滤器(Cuckoo Filter) : Cuckoo Filter 是另一种概率性集合,它允许删除元素,并且相较于布隆过滤器在某些场景下提供了更好的性能和灵活性。与布隆过滤器相比,Cuckoo Filter 的误判率通常更低,并且支持元素删除,但是占用内存较高。
Top-K:Top-K 数据结构用于跟踪某个集合中出现频率最高的前 K 个元素。它以节省内存的方式进行频率统计,适用于大数据集合。
布隆过滤器的优势
内存效率高:
布隆过滤器相比于哈希表或其他数据结构具有极高的内存效率,尤其在处理大量数据时尤为显著。它通过位数组来表示元素是否存在,而不需要存储元素本身,因此节省了大量空间。
通过调整过滤器的参数(如哈希函数数量、位数组大小等),可以在一定范围内控制误判率和内存占用之间的平衡。
高效的查询速度:
布隆过滤器的查询速度非常快,因为它只需要通过多个哈希函数对元素进行多次哈希计算,然后检查位数组的若干个位置是否为 1,这一过程通常是 O(1) 时间复杂度。
在高并发环境中,布隆过滤器能够保持很高的性能,适合对大量数据进行快速判断。
无锁并发读写:
- 布隆过滤器可以在没有锁机制的情况下进行并发读写操作。由于其操作过程仅涉及哈希函数的计算和位数组的更新,不存在复杂的数据竞争问题,因此适合在多线程环境下使用。
可灵活调整误判率: 布隆过滤器的误判率是可以通过配置来调整的。通过选择合适的哈希函数数量和位数组大小,可以在内存占用和误判率之间找到最佳平衡点。
布隆过滤器的缺点
存在误判(假阳性):
布隆过滤器会出现假阳性,即可能会误判一个元素存在于集合中,但实际上它并不在集合中。这是因为不同元素的哈希值可能映射到相同的位置,导致误判。
误判率可以通过增加位数组大小和哈希函数数量来降低,但无法完全避免。误判率的大小与布隆过滤器的设计参数相关联。
不支持删除操作:
一旦某个元素被插入到布隆过滤器中,就无法直接删除该元素。因为删除某个元素会影响其他元素的哈希值映射,可能导致其他元素的查询结果出现错误。因此,布隆过滤器适合那些只增不删的场景。
有改进版本如计数布隆过滤器(Counting Bloom Filter),通过计数器来实现删除功能,但内存开销相对增加。
误判率随数据量增加而上升:
随着插入的元素增多,布隆过滤器的误判率会增加。这是因为哈希映射的位位置会越来越多地被填满,导致更多的哈希冲突。如果要维持较低的误判率,必须预估好数据量,并设置足够大的位数组。
如果未能提前规划好数据量,布隆过滤器的性能和准确性会随着数据量的增加而下降。
不支持获取元素: 布隆过滤器只能判断某个元素是否存在,而无法获取元素的实际值或相关信息。它适合用于快速筛选数据,而不能用于存储或查找具体的数据内容。
布隆过滤器的应用场景
防止缓存穿透:
在分布式缓存系统中(如 Redis 缓存),缓存穿透是指查询大量不存在的 key,导致这些查询绕过缓存,直接打到数据库上,增加数据库负载。通过使用布隆过滤器,将所有可能存在的合法 key 哈希到过滤器中,查询时先判断 key 是否存在。如果布隆过滤器判定不存在,则直接返回空,避免直接访问数据库。
应用场景:电商平台、社交平台的用户请求缓存,避免频繁请求不存在的商品、帖子或用户信息。
大规模反垃圾、黑名单过滤:
布隆过滤器可以用于快速判断一个用户或 IP 是否在黑名单中。通过预先将黑名单数据哈希到布隆过滤器中,可以在接收到请求时快速筛查是否为黑名单用户,进行相应处理。
应用场景:反垃圾邮件系统、防火墙、恶意 IP 拦截等。
爬虫 URL 去重:
在网络爬虫中,爬虫需要不断记录访问过的 URL 以避免重复抓取同一页面。使用布隆过滤器可以有效地去重 URL,尤其是在处理亿级甚至更大规模的数据时。
应用场景:搜索引擎爬虫系统,避免重复抓取同一个网站或页面。
去重系统:
在需要高效去重的场景下,布隆过滤器能够快速判断元素是否已经存在,例如日志系统中去除重复日志、系统中去除重复请求、数据处理中去除重复记录等。
应用场景:大数据去重、日志去重等。
区块链和 P2P 网络:
在区块链和 P2P 网络中,布隆过滤器常用于交易或消息的快速检索。例如,在比特币网络中,布隆过滤器被用于快速查询节点是否包含某些特定交易信息,从而减少网络通信和存储开销。
应用场景:区块链交易过滤、P2P 网络节点消息过滤。
搜索引擎中的关键词匹配:
搜索引擎中的关键词查询可以利用布隆过滤器快速判断关键词是否存在于索引中,减少不必要的磁盘访问。
应用场景:关键词匹配、广告系统中的点击去重。
安装 RedisBloom模块
访问官网:https://github.com/RedisBloom/RedisBloom,选择合适的版本进行下载安装。
编译RedisBloom源码
在Linux环境下,执行命令:
1 | |
解压完成后,在 /RedisBloom-2.2.18 文件夹中,就可以看到编译好的 redisbloom.so 文件了。
新建 modules 文件夹
在 F:\Docker\Redis 目录下创建一个 /modules 模块文件夹,如下: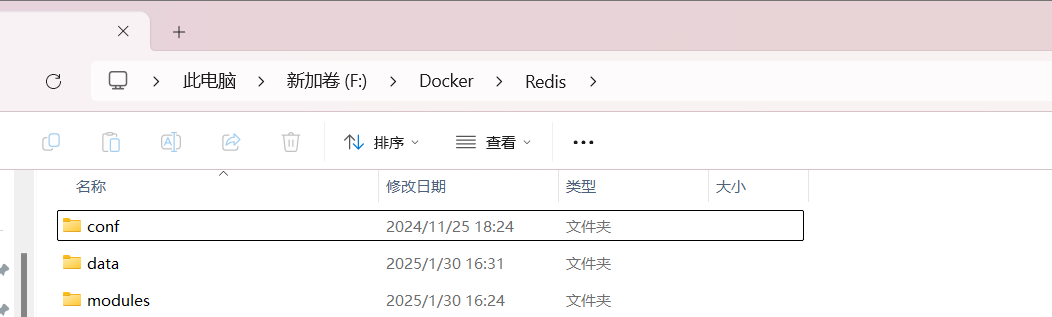
将编译好的 redisbloom.so 文件放进去。
添加配置
编辑 F:\Docker\Redis\conf 配置文件,搜索关键字 loadmodule ,找到配置加载模块的位置。
添加配置:
1 | |
更新 Redis 容器
删除原本的Redis容器,执行以下语句创建新容器:
1 | |
新增命令参数:-v F:\Docker\Redis\modules:/etc/redis/modules,目的是为了将模块存放的文件夹挂载到宿主机中。
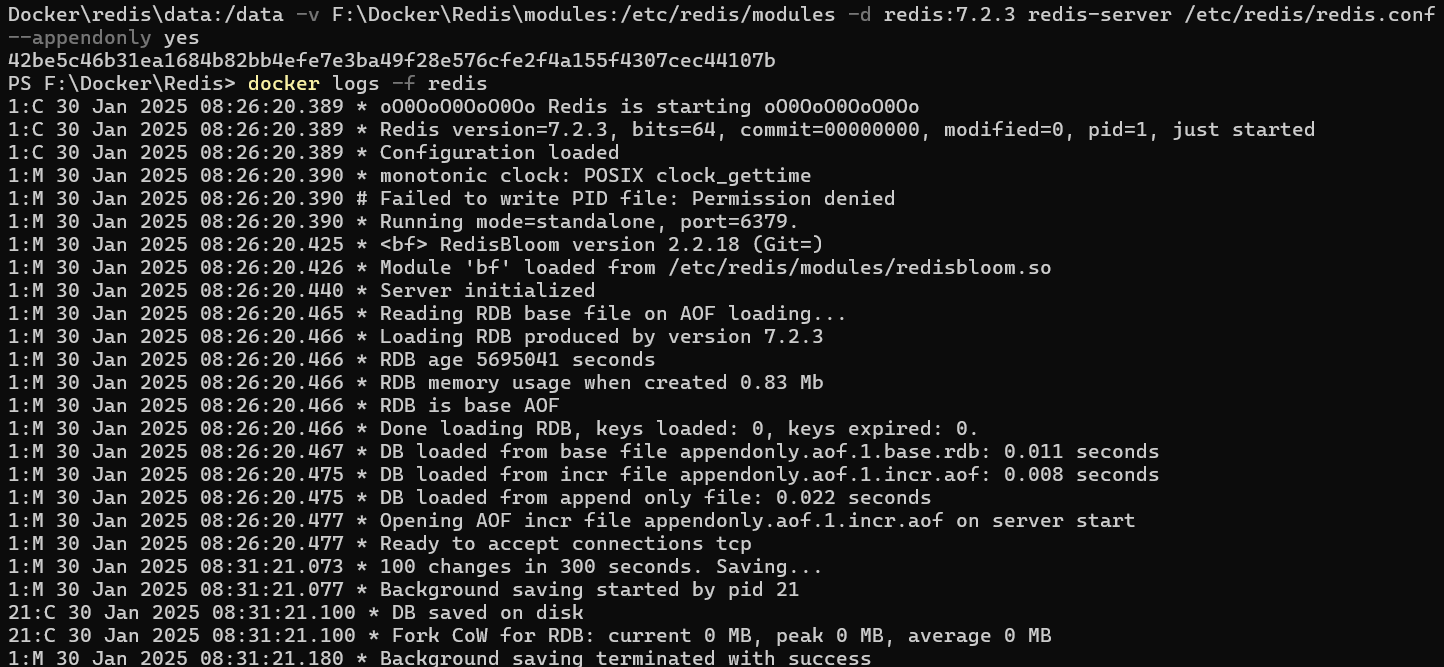
执行完成后,输入以下指令查看是否挂载成功:
1 | |
若有 Module 'bf' loaded from /etc/redis/modules/redisbloom.so 提示信息,则表示 RedisBloom 模块加载成功了。